
Page 60 - Summer2020
P. 60
SPEECH ACOUSTICS
is characterized by longer, irregular, cycles and a shallow falloff in spectral energy.
Many languages employ differences in voice quality as a feature of lexical tone (the use of vocal pitch, for which the fundamental frequency is the acoustic correlate, to distinguish words), as in Mandarin and Vietnamese. For example, Mandarin has four main lexical tones (see Multimedia1 at acousticstoday.org/tuckermedia): high level (as in the word “eight” 八 [pa˥]), mid-high rising (as in the word “to pull out” 拔 [pa˧˥]), mid-low-mid dip- ping (as in the word “to hold” 保 [pa˨˩˦]), and high-low falling (as in the word “father” 爸 [pa˥˩]). In the mid- low-mid dipping tone, creaky voicing is used. In other languages, fundamental frequency and voice quality can be used to convey meaning at the sentence level, as in English questions versus statements (see Multimedia2 at acousticstoday.org/tuckermedia). Statements end in a low pitch that is often accompanied by creaky voicing.
Many other languages have contrastive (or phonemic) voice quality. Linguists use meaning differentiation to determine when speech sounds are contrastive in a
language. For example, in English, sit and zit mean dif- ferent things and are minimally contrastive; the sounds [s] and [z] are only distinguished by vocal-fold vibration, which is what differentiates the two words. One language that makes contrasts based on voice quality is Jalapa de Días Mazatec, an Otomanguean language spoken by about 17,500 speakers in Mexico (Eberhard et al., 2019). Figure 5 illustrates two words where voice quality differences on the vowels conveys different meanings. In Figure 5A, [thæ], “itch” (see Multimedia3 at acousticstoday.org/tuckermedia), the vocalic portion is modally voiced with regular cycles and a level amplitude. In Figure 5B, [thæ̰ ], “sorcery” (see Multimedia4 at acousticstoday.org/tuckermedia), the vowel is realized with creaky (also known as laryngealized) voicing. The lower amplitude and longer and irregular cycles of creaky voicing can be seen between 225 and 300 ms in Figure 5B.
Some consonants, typically referred to as approximants, have dynamic vowel-like resonances, such as [w]. Like vowels, they are best defined in terms of their first three resonances (F1, F2, and F3). All other consonants can be described in terms of their place of articulation or where in the oral tract they are produced. These places of
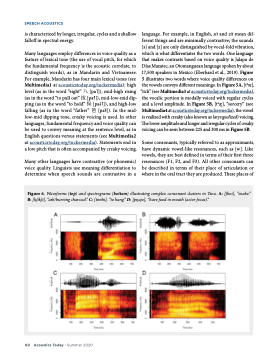
Figure 6. Waveforms (top) and spectrograms (bottom) illustrating complex consonant clusters in Tsou. A: [fkoi], “snake.” B: [kʃikʃi], “ash/burning charcoal.” C: [tmihi], “to hang.” D: [pŋajo], “have food in mouth (actor focus).”
60 Acoustics Today • Summer 2020
