
Page 54 - 2016Winter
P. 54
Speech Production Research
mappings allowed us to take audio recordings, which are easy to make, and estimate vocal tract features, such as the source of voice qualities like hoarseness, tongue position in different accents and languages, or the subject identifiers used in forensics. Unfortunately, inverse maps are not one- to-one. A single acoustic spectrum can be produced by more than one vocal tract shape. This is easily exemplified by ven- triloquists who routinely produce acoustic features associ- ated with lip motion using other parts of the vocal tract.
Strong evidence for a many-to-one relationship between vo- cal tract shapes and an acoustic spectrum came from two sources. The first source was a series of studies that measured vowels while the jaw was held rigid by a bite block inserted between the molars like the stem of a smoker’s pipe. Speech acoustics and perception were the same with and without the bite block, indicating that the subjects had found a different articulatory position to produce the same vowel (Gay et al., 1981) and alveolar consonant (Flege et al., 1988) sounds. The second source was acoustic-to-articulatory inversion stud- ies, which used vocal tract models to show that many differ- ent vocal tract shapes could produce a specific sound (Atal et al., 1978).
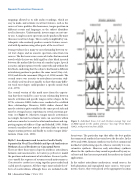
The second version of this myth arose from the expecta- tion that there would be a one-to-one relationship between muscle activation and specific tongue surface shapes. In the 1970s, extensive EMG studies were conducted to establish these relationships. However, EMG studies showed that muscle activity is quite variable for the same speech task and must be averaged across repetitions to reveal activation pat- terns (see Figure 3). Moreover, tongue muscle activation is not simple. Instead, local motor units can coactivate within and across muscles to create local internal motions and sup- porting regions of stiffness (Cope and Sokoloff, 1999). Other research considers how muscle activation links to internal tongue motion patterns and finally to surface tongue defor- mations (Stone et al., 2008).
Myth 7: Aerodynamics and Acoustics Can Be Neatly Separated in Vocal Tract Models and Speech Synthesizers Without a Loss of Predictive or Conceptual Power
There are three basic types of speech synthesis: articulatory, formant, and concatenative. Articulatory synthesizers model the positions and movement of articulators. Formant synthe- sizers model the sequence of resonances and antiresonances. Concatenative synthesizers string together prerecorded and coded speech segments. All three types must include the ef- fects of coarticulation, although these are included in dif-
52 | Acoustics Today | Winter 2016
Figure 3. Individual (rows 2-5) and 20-token average (top row) of EMG signals for the spoken utterance “fax map.” From Harris (1982), with permission from ASHA.
ferent ways. The particular type that offers the best quality for commercial synthesis has varied over the decades. In the 1970s and 1980s, formant synthesis was the best commercial method of synthesizing speech, whereas currently it is con- catenative synthesis. However, only articulatory synthesis allows for the synthesis of any sound as produced by any vo- cal tract and thus has more potential for synthesis in clinical applications.
In the earliest articulatory synthesizers, sound sources, for both phonation and supraglottal noise sources, were para- metric, that is, they were placed at the appropriate location
